パラレルストリーミング処理(Parallel Stream Processing、以下:PSP)は、DataSpider Cloudでメモリ消費を抑えながら大容量データを高速に処理する機構です。
PSPは、以下のような特徴を持っています。
- メモリ消費の抑制
入力データをすべてメモリに保持せず、1000件ずつ「読み取り」-「変換」-「書き込み」の処理を行います。
そのため、大量のメモリを必要とすることなく大容量のデータを処理することができます。
- 超大容量データ処理
入力データをメモリに保持せず処理するため、理論上、データ容量の制限はありません。
- パフォーマンスの向上
「読み取り」-「変換」-「書き込み」を順番に処理する場合、CPU資源を有効に使えていません。
PSPを利用することにより、読み取り、変換、書き込みの各処理をマルチスレッドで動作し処理を分散させるため、1つの処理がI/O待ちになっている状態でも、ほかのスレッドで変換などの処理を並行で行えるようになります。
パラレルストリーミング処理のアーキテクチャ
PSPは以下のアーキテクチャで動作します。読み込み処理、変換処理、書き込み処理をブロック単位で同時に別々のスレッドで処理します。
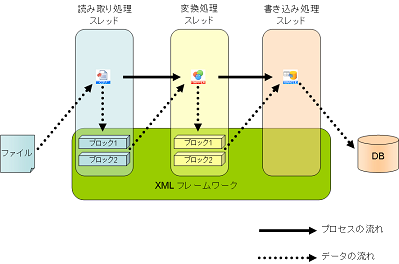
結果データを生成する(上図では、読み取り処理および変換処理)コンポーネントは、内部的に結果データを格納するブロック(たとえば1000行単位)を2つ保持するようになっています。
結果データを生成するコンポーネントは書き込み可能な状態(データが消費されている状態)のブロックを検出すると、書き込み処理を行います。書き込み可能なブロックを検出できない状態(データが消費されていない状態)では、処理を待機します。
結果データを使用するコンポーネント(上図では、変換処理および書き込み処理)は、入力元のコンポーネントの結果データに、読み取り可能な状態(データの生成が完了した状態)のブロックを検出すると処理を開始します。読み取り可能なブロックを検出できない状態(データの生成が未完了な状態)では処理を待機します。
処理の流れ
「読み取り」-「変換」-「書き込み」の簡単なサンプルで、処理の流れを処理ステップごとに説明します。
各ステップのデータa、データb、データcは、読み取り用データの1ブロックを表します。
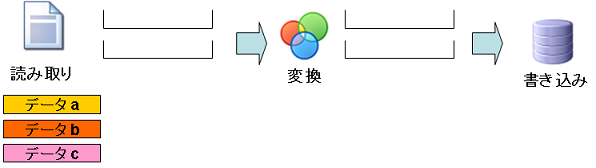
ステップ1:処理前
- データa:まだ読み込まれていません。
- データb:まだ読み込まれていません。
- データc:まだ読み込まれていません。
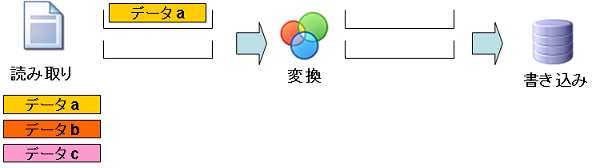
ステップ2:「データa」の読み取り
- データa:読み取り処理で読み込まれ、読み取りコンポーネントのブロックに格納されます。
- データb:まだ読み込まれていません。
- データc:まだ読み込まれていません。
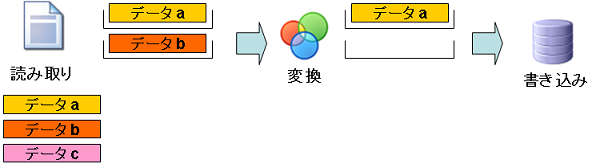
ステップ3:「データb」の読み取りと「データa」の変換
- データa:変換処理で変換され、変換コンポーネントのブロックに格納されます。
- データb:読み取り処理で読み込まれ、読み取りコンポーネントのブロックに格納されます。
- データc:まだ読み込まれていません。
 すべての処理が並行で行われます。
すべての処理が並行で行われます。
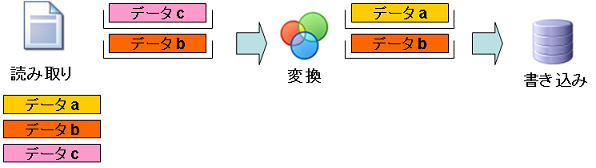
ステップ4:「データc」の読み取りと「データb」の変換および「データa」の書き込み
- データa:書き込み処理で実際にデータが書き込まれます。また、変換処理が完了しているので、読み取り処理のブロックから削除されます。
- データb:変換処理で変換され、変換コンポーネントのブロックに格納されます。
- データc:読み取りコンポーネントのブロックが空いたので、読み取り処理で読み込まれ、読み取りコンポーネントのブロックに格納されます。
すべての処理が並行で行われます。
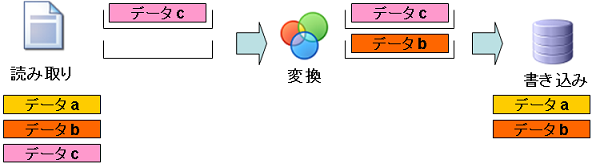
ステップ5:「データc」の変換と「データb」の書き込み
- データa:書き込み処理まで終了しています。
- データb:書き込み処理で実際にデータが書き込まれます。また、変換処理が完了しているので、読み取り処理のブロックから削除されます。
- データc:変換処理で変換され、変換コンポーネントのブロックに格納されます。
すべての処理が並行で行われます。
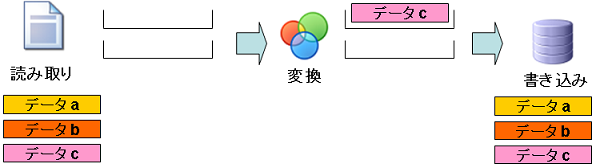
ステップ6:「データc」の書き込み
- データa:書き込み処理まで終了しています。
- データb:書き込み処理まで終了しています。
- データc:書き込み処理で実際にデータが書き込まれます。また、変換処理が完了しているので、読み取り処理のブロックから削除されます。
すべての処理が並行で行われます。
このように、データをブロック単位に分割し、そのブロック単位を並行して処理することで、超大容量データを高速に処理しています。
スマートコンパイラにより、スクリプトの内容を自動判別してパラレルストリーミング処理を適用します。
そのため、基本的にはパラレルストリーミングを意識することなくスクリプトを作成することが可能です。
 詳細については、「スマートコンパイラ」を参照してください。
PSPに対応するコンポーネントとMapperロジックについてはヘルプを参照してください。
詳細については、「スマートコンパイラ」を参照してください。
PSPに対応するコンポーネントとMapperロジックについてはヘルプを参照してください。
PSPに対応するコンポーネントのオペレーションについては、各オペレーションのページを参照してください。
PSPに対応するMapperロジックについては、「Mapperロジック一覧」を参照してください。
前項で説明したように、PSPでは複数のスレッドが協調して処理を行います。
PSPではスクリプトのスレッドのほかに、結果データを生成する(入力元となる)コンポーネントの数だけスレッドが生成されます。結果データを生成しない書き込みコンポーネントに関しては、スクリプトと同じスレッドで動作します。
たとえば、「読み取り」-「変換」-「書き込み」のスクリプトでは、生成するスレッド数は「3」となります。
「読み取り」-「変換」-「変換」-「書き込み」のスクリプトでは、生成するスレッド数は「4」となります。
- トランザクションが開始していた場合、PSPで実行するコンポーネントはそのトランザクションに属します。
- トランザクションが開始していない場合、PSPで実行するコンポーネントは専用のトランザクションを開始します。
そのため、同じグローバルリソースを使用するコンポーネントが複数存在し、いずれかがPSPで実行する場合、別々のコネクションを使用します。
- PSPでは、結果データを複数のコンポーネントの入力元に指定することはできません。
- 変数Mapperで、入力ドキュメントから変数にマッピングしている場合も入力元への指定にあたります。
- エラーについて
- PSPでは、読み取りや変換コンポーネントで発生したエラーは、書き込みコンポーネントのエラーとして処理されます。エラーの内容については、PSPカテゴリのメッセージコードを確認してください。
- PSPでは、読み取りや変換コンポーネントで発生したエラーは、変換コンポーネントを入力元に取るコンポーネントが存在しない場合には、エラーとして処理されません。
たとえば、PSPが適用されている読み取りコンポーネントでエラーが発生しても、スクリプトは成功し、エラーメッセージはログに出力されません。
- PSPで処理を行う読み取りコンポーネントと書き込みコンポーネントの間で、処理対象となるファイルは操作できません。
- PSPでは、一部のコンポーネント変数が使用できません。
詳細については、各オペレーションのヘルプを参照してください。
- PSPでは、結果データを作成するコンポーネントが実行された際にスレッドが作成されます。
- ブロックサイズを変更することはできません。
- 引数からのデータフローやMapper間のデータフローの場合には、Mapperで「スキーマの設定」を行うことができますが、「テーブルモデル型」以外のスキーマに変更すると PSP対応Mapperとして動作しません。
つまり、大容量のデータを扱う場合にはメモリを確保する必要があります。PSPを適用する場合には、Mapperのスキーマをテーブルモデル型以外のスキーマ(「XML型」)に変更しないようにしてください。