DataSpider Cloudでは、処理コンポーネント間でのデータの受け渡しをする際には、必ずこのXML Frameworkを介して処理を行います。そのためXML Frameworkは、DataSpider Cloudのデータハンドリングの心臓部にあたるといえます。
XML Frameworkの役割
XML Frameworkを経由してデータをやり取りすることにより、各処理コンポーネントはお互いにデータを透過的に扱えるようになります。
XML Frameworkには大きく2つの役割があります。
- データの保存形式の差異の吸収
DataSpider Cloudでは、処理コンポーネントごとに大容量データを扱うようにするかどうかの設定が可能となっています。大容量データ処理を有効にしなかった場合と有効にした場合とでは結果データの内部的なデータ保存形式が異なります。
大容量データ処理を有効にしなかった場合には、結果データはメモリ上に保存され、大容量データ処理を有効にした場合には結果データはファイルに保存されます。
結果データの保存形式がメモリ上であってもファイルであっても、処理コンポーネントから見た場合、XML Frameworkが保存形式の差異を吸収し、単一のデータ形式に見えるため、処理コンポーネントの実装が保存形式に依存しない形になっています。
- データモデルの差異の吸収
内部データモデルには、構造を柔軟に扱うことができる「XML型」と、高速処理や大容量データ処理に適応した「テーブルモデル型」があります。
内部的には2つのデータモデルが存在するものの、処理コンポーネントから見て、ここでもXML Frameworkがデータモデルの差異を吸収し、単一のデータモデルとして扱うことが可能となっています。
XML Frameworkを経由することにより、処理コンポーネント同士はお互いに緩やかな結合となり、ある処理コンポーネントの設定や状態の変更が、ほかの処理コンポーネントに影響をおよぼさなくなります。
たとえば、データベースからCSVにデータを書き込む処理を作成した場合、当初はデータ量が少なく大容量データ処理を有効化せずに実行していたスクリプトが、要求の変更により大容量データの読み取りをサポートしなければならない状況になったとしても、データベースアダプタ読み取り処理の大容量データの設定を有効にするだけです。
書き込み対象のCSVアダプタの設定は一切変更する必要はありません。また、CSVに書き出すのではなく、XML文書に書き出すように変更があった場合でも、単にCSVアダプタをXMLアダプタに変更するだけです。
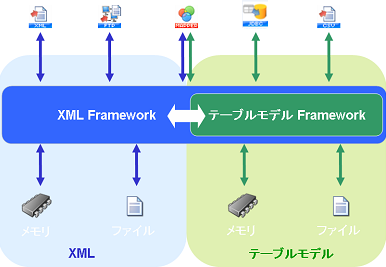 XML Frameworkで使用されているデータモデルは、テーブルモデル型とXML型があります。
XML Frameworkで使用されているデータモデルは、テーブルモデル型とXML型があります。
テーブルモデル型
テーブルモデル型とは、データを高速に処理(読み取り・変換・書き込み)するためのデータモデルです。
テーブルモデル型はCSV形式のデータやデータベースのレコード/カラム情報など、二次元配列として表現できるデータモデルを扱う際に適しています。
テーブルモデル型は実際のデータ(データベースの場合にはデータベースから抽出したデータ)以外の情報はほとんど生成されないため、非常にコンパクトなデータモデルとなっています。また、内部では、配列にアクセスするのと同様のデータアクセス速度となるため、非常に高速に処理を行うことができます。
 テーブルモデル型に対応しているコンポーネントについては、各アダプタの「データモデル」の項を参照してください。
テーブルモデル型のスキーマ構造は以下の通りです。基本的に「行」、「列」の情報を保持しています。
テーブルモデル型に対応しているコンポーネントについては、各アダプタの「データモデル」の項を参照してください。
テーブルモデル型のスキーマ構造は以下の通りです。基本的に「行」、「列」の情報を保持しています。
<table>
<row>
<column></column>
<column></column>
:
</row>
<row>
<column></column>
<column></column>
:
</row>
:
</table>
テーブルモデル型は上記のように同一のスキーマであるため、テーブルモデル型同士のデータの入出力の際に、値の変換やカラム順序の変換がない場合にはMapperは必要ありません。
Mapperを使用しない場合には、カラム順序は出現順序で処理されます。
Mapperとの関係
Mapperの入出力スキーマにテーブルモデル型のコンポーネントを指定した場合には、テーブルモデル型専用の変換エンジンに切り替えられます。テーブルモデル型専用の変換エンジンは大容量データに対応しており、非常に高速に変換処理が行われます。
テーブルモデル型専用変換エンジンは一部ロジックを除き、row要素(行)のループのみとなり、row要素(行)を超えての値のマッピングを行うことはできません。つまり、1行目の内容を2行目の内容に含めることはできません。
また、テーブルモデル型のコンポーネントをMapperの入力元または出力先とした場合、入出力スキーマの読み込みを行う必要はありません。
XML型
XML型とはデータを中間データとしてXML文字列で保持するデータモデルです。
XML型は構造を自由に設計できるため、処理によって構造が異なる場合に適しています。
XML型に対応している処理コンポーネントについては、各アダプタの「データモデル」の項を参照してください。
処理コンポーネントや操作によって異なります。
Salesforceアダプタのように、オブジェクトの項目からスキーマ生成するものもあれば、XMLアダプタなどのように特にスキーマを持たないもの、FTPアダプタのように固定のスキーマを持つものなどがあります。
Mapperとの関係
XML型がMapperの入出力のどちらかに設定された場合には、繰り返しのノードを自由に指定することができます。
これは、構造を自由に変換できることを意味します。
このようにXML型は非常に柔軟ではありますが、Mapper内部ではDOM(Document Object Model)形式で処理されるため、メモリ使用量が多くなります。そのため、大容量のデータを扱う際は、DataSpiderServerのヒープサイズを確保する必要があります。
サーバのヒープサイズを変更する場合、メモリ容量の拡大が必要になるため別途お問い合わせください。
また、XML型のコンポーネントをMapperの入力元または出力先とした場合、一部コンポーネントを除き、入出力スキーマの読み込みを行う必要があります。
大容量データ処理とは
通常の処理はすべてのデータをメモリ中に保持しますが、大容量データ処理は処理に必要な最低限のデータのみメモリに格納し、ほかのデータをファイルに保存することで、大容量のデータの処理を実現することができます。
コンポーネントの処理で大容量のデータを扱う場合(主にアダプタの読み込み処理)に、スクリプトの設定もしくはアダプタの設定で[大容量データ処理を行う]を選択します。
テーブルモデル型のすべてのアダプタおよび、一部のXML型アダプタ([大容量データ処理]タブがあるのもの)、Mapperが大容量データ処理に対応しています。
大容量データ処理を行った場合、テーブルモデル型コンポーネント、XML型コンポーネント、Mapperいずれも結果データをメモリ中に保持するのではなく、DataSpiderServerローカルのファイルに保存します。メモリ中には実際に処理を行うために必要な最小限のデータだけが格納されます。
XML型では固定のバッファサイズ分、もしくは1ノードあたりのデータ単位でメモリに格納されています。
テーブルモデル型では1行分のデータ単位でメモリに格納されます。1行分読み終えると、ファイルに保存されます。ファイルに書き出される際には書き込みバッファにデータが書き込まれるため、実際に1行ごとにファイルに書き込まれているわけではありません。
結果データをファイルに保存するため、結果データ分(XML型の場合には要素名などのデータ量も考慮に入れる必要があります。)のディスク空き容量が必要となります。生成されるファイルは結果データを使用するスクリプト処理が終了するタイミングで削除されます。
 大容量データ処理に未対応のコンポーネントで大容量のデータを扱う際は、DataSpiderServerのヒープサイズを確保する必要があります。
大容量データ処理に未対応のコンポーネントで大容量のデータを扱う際は、DataSpiderServerのヒープサイズを確保する必要があります。
(入力元のコンポーネントが大容量データ処理を行っていた場合でも、結果データを受け取るコンポーネントが大容量データ処理に対応していないのであれば、大容量のデータをメモリ中に保持することになります。)
サーバのヒープサイズを変更する場合、メモリ容量の拡大が必要になるため別途お問い合わせください。
 DataSpider Cloudでは、大容量データ処理以外にも、大容量データに対応した機能があります。詳細については、「大容量データの対応」を参照してください。
DataSpider Cloudでは、大容量データ処理以外にも、大容量データに対応した機能があります。詳細については、「大容量データの対応」を参照してください。