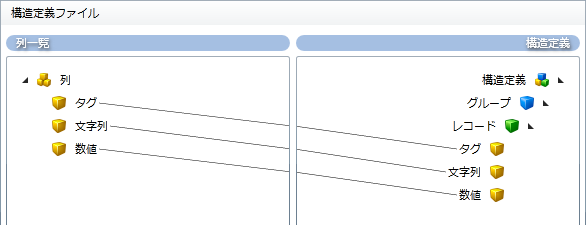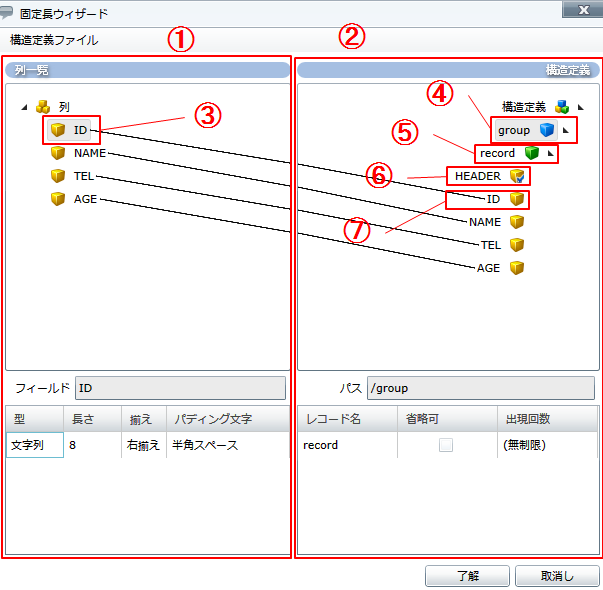
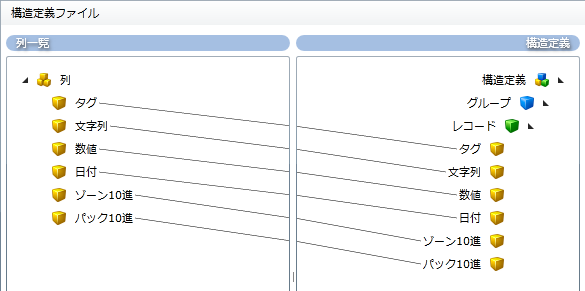
入力データの列数と同数のフィールドを追加し、各フィールドに対して構造(名前、型、長さ、揃え、パディングなど)を定義します。
- 列一覧はテーブルモデル型と同様の構造です。
 テーブルモデル型については、「データモデル」を参照してください。
テーブルモデル型については、「データモデル」を参照してください。
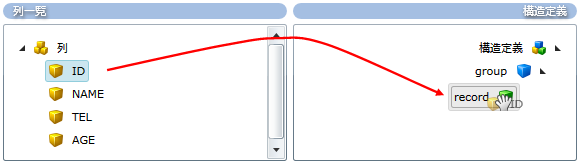
構造定義ではグループ、レコードを定義し、そこに列一覧で定義したフィールドをドラッグ&ドロップで追加します。
- フィールドは黄色のアイコンで表現されます。
- グループは青色のアイコンで表現されます。
- レコードは緑色のアイコンで表現されます。
- 固定フィールドは黄色のアイコン(チェック付き)で表現されます。
- フィールドは黄色のアイコンで表現されます。
 ニブルとは、情報量の単位の1つで、4ビットに相当します。
ニブルとは、情報量の単位の1つで、4ビットに相当します。
 ファイルパスはDataSpider Cloudファイルシステムの絶対パスで指定してください。
ファイルパスはDataSpider Cloudファイルシステムの絶対パスで指定してください。