ユーザが自由に作成および追加を行うことができます。
(変数Mapperを使用します。)
 詳細については、「スクリプト変数」を参照してください。
詳細については、「スクリプト変数」を参照してください。
コンポーネントで発生したエラーや、処理したデータの数などを取得することができます。
(コンポーネントの実行時に自動的に設定されます。)
 コンポーネントの実行時にデフォルト値で初期化されます。
コンポーネントの実行時にデフォルト値で初期化されます。- 詳細については、各アダプタのオペレーションのページを参照してください。
ユーザが自由に作成および追加を行うことができます。
- 詳細については、「環境変数管理」を参照してください。
- 詳細については、「トリガー」および各トリガーガイドを参照してください。

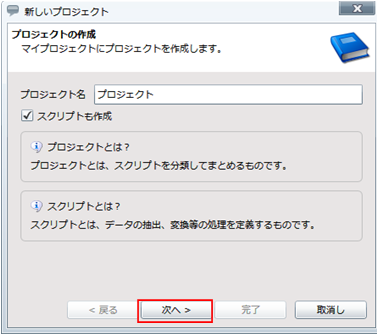
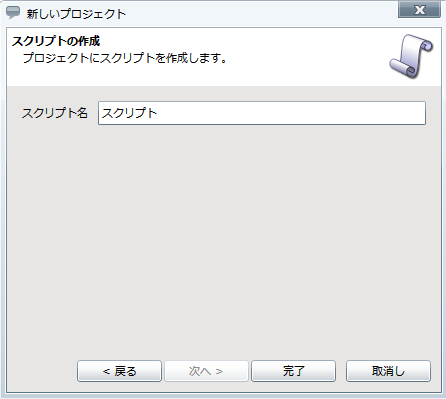
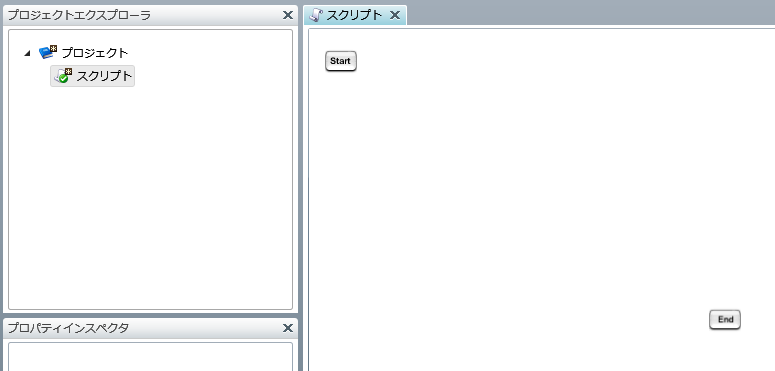




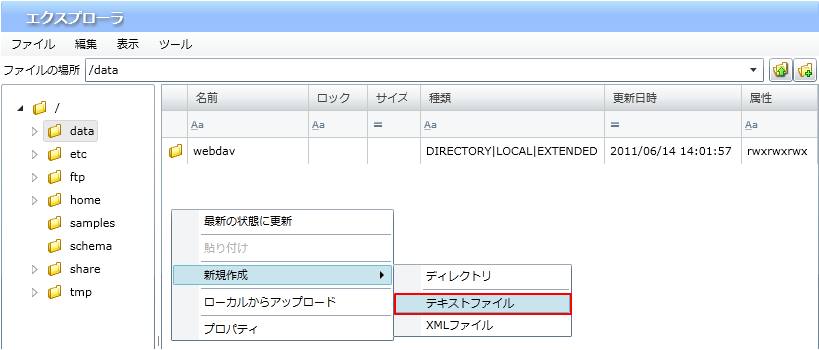
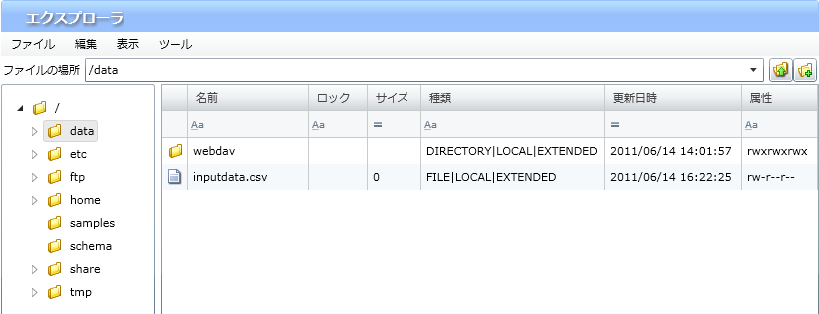
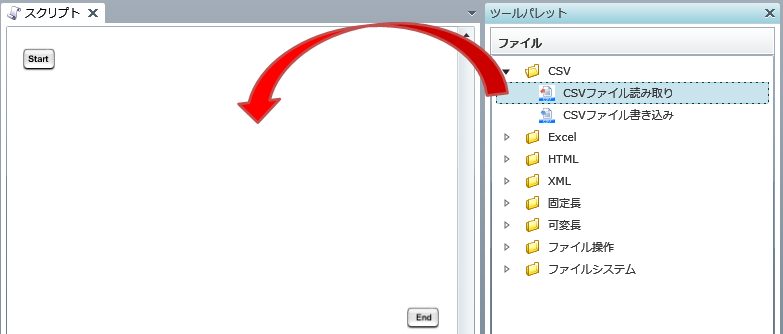
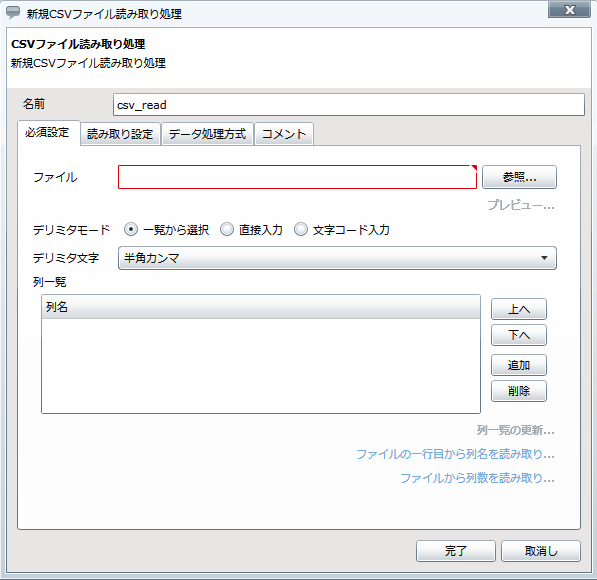
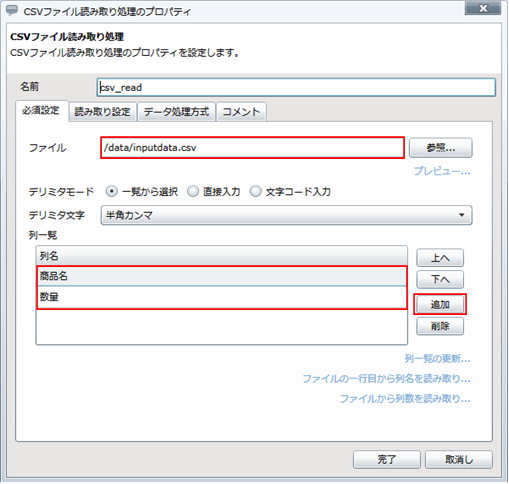
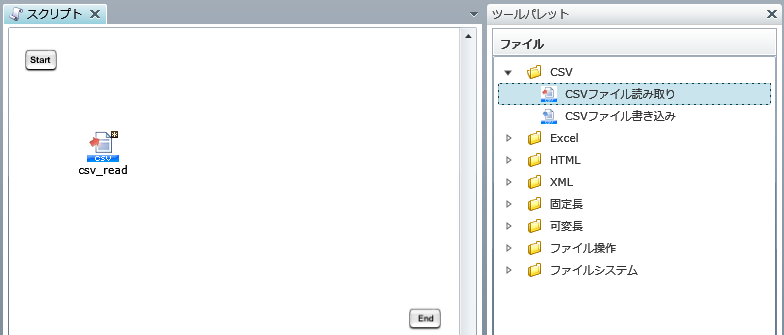
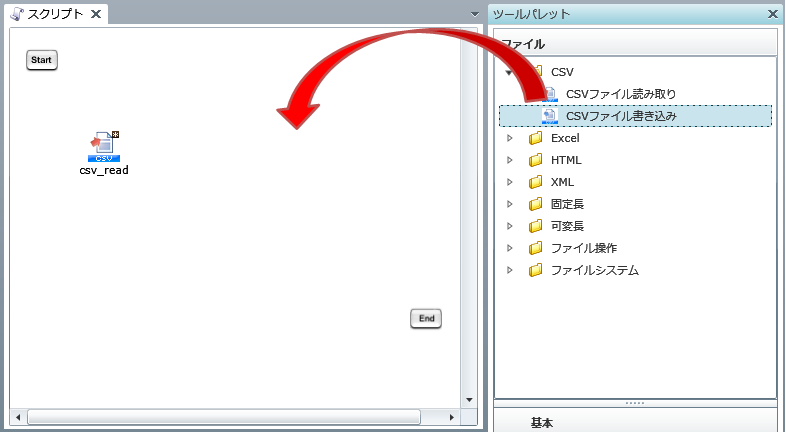
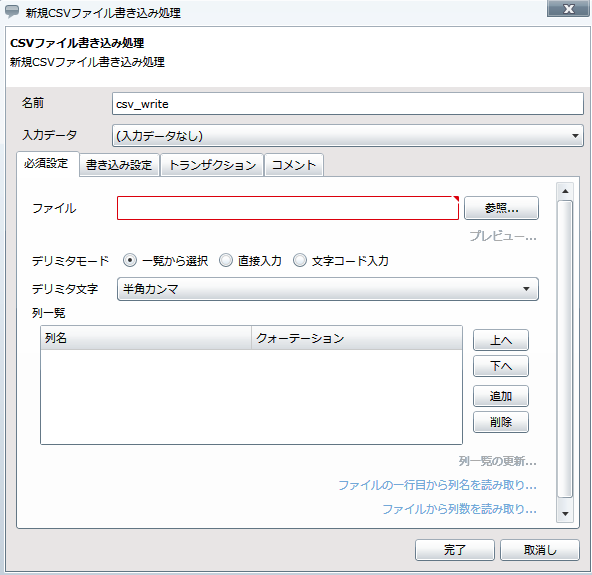
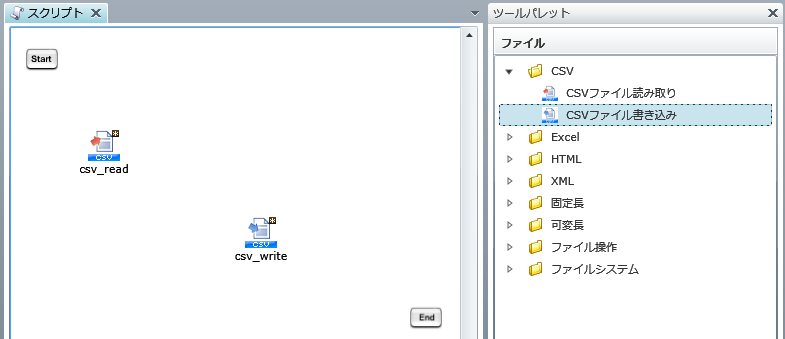
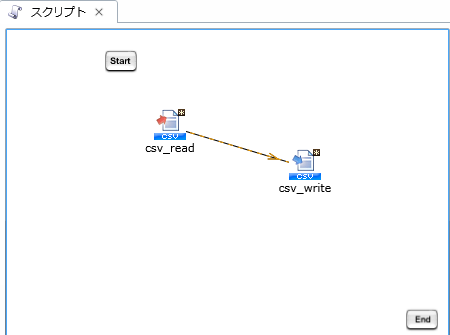
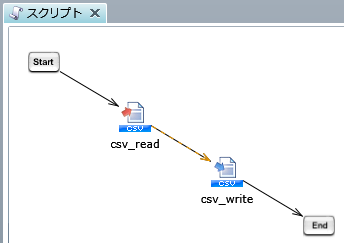
 プロジェクトを保存している最中に、サーバを再起動したり、クライアントとサーバとのネットワークが切断されたりした場合などに、プロジェクトが不正な状態で保存され、再度開くことができなくなることがあります。
プロジェクトを保存している最中に、サーバを再起動したり、クライアントとサーバとのネットワークが切断されたりした場合などに、プロジェクトが不正な状態で保存され、再度開くことができなくなることがあります。