僷儔儗儖僗僩儕乕儈儞僌張棟(Parallel Stream Processing丄埲壓:PSP)偼丄DataSpider Cloud偱儊儌儕徚旓傪梷偊側偑傜戝梕検僨乕僞傪崅懍偵張棟偡傞婡峔偱偡丅
PSP偼丄埲壓偺傛偆側摿挜傪帩偭偰偄傑偡丅
- 儊儌儕徚旓偺梷惂
擖椡僨乕僞傪偡傋偰儊儌儕偵曐帩偣偢丄1000審偢偮乽撉傒庢傝乿-乽曄姺乿-乽彂偒崬傒乿偺張棟傪峴偄傑偡丅
偦偺偨傔丄戝検偺儊儌儕傪昁梫偲偡傞偙偲側偔戝梕検偺僨乕僞傪張棟偡傞偙偲偑偱偒傑偡丅
- 挻戝梕検僨乕僞張棟
擖椡僨乕僞傪儊儌儕偵曐帩偣偢張棟偡傞偨傔丄棟榑忋丄僨乕僞梕検偺惂尷偼偁傝傑偣傫丅
- 僷僼僅乕儅儞僗偺岦忋
乽撉傒庢傝乿-乽曄姺乿-乽彂偒崬傒乿傪弴斣偵張棟偡傞応崌丄CPU帒尮傪桳岠偵巊偊偰偄傑偣傫丅
PSP傪棙梡偡傞偙偲偵傛傝丄撉傒庢傝丄曄姺丄彂偒崬傒偺奺張棟傪儅儖僠僗儗僢僪偱摦嶌偟張棟傪暘嶶偝偣傞偨傔丄1偮偺張棟偑I/O懸偪偵側偭偰偄傞忬懺偱傕丄傎偐偺僗儗僢僪偱曄姺側偳偺張棟傪暲峴偱峴偊傞傛偆偵側傝傑偡丅
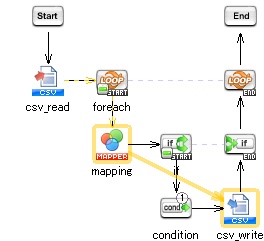
僷儔儗儖僗僩儕乕儈儞僌張棟偺傾乕僉僥僋僠儍
PSP偼埲壓偺傾乕僉僥僋僠儍偱摦嶌偟傑偡丅撉傒崬傒張棟丄曄姺張棟丄彂偒崬傒張棟傪僽儘僢僋扨埵偱摨帪偵暿乆偺僗儗僢僪偱張棟偟傑偡丅
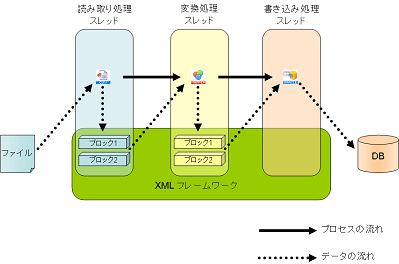
寢壥僨乕僞傪惗惉偡傞(忋恾偱偼丄撉傒庢傝張棟偍傛傃曄姺張棟)僐儞億乕僱儞僩偼丄撪晹揑偵寢壥僨乕僞傪奿擺偡傞僽儘僢僋(偨偲偊偽1000峴扨埵)傪2偮曐帩偡傞傛偆偵側偭偰偄傑偡丅
寢壥僨乕僞傪惗惉偡傞僐儞億乕僱儞僩偼彂偒崬傒壜擻側忬懺(僨乕僞偑徚旓偝傟偰偄傞忬懺)偺僽儘僢僋傪専弌偡傞偲丄彂偒崬傒張棟傪峴偄傑偡丅彂偒崬傒壜擻側僽儘僢僋傪専弌偱偒側偄忬懺(僨乕僞偑徚旓偝傟偰偄側偄忬懺)偱偼丄張棟傪懸婡偟傑偡丅
寢壥僨乕僞傪巊梡偡傞僐儞億乕僱儞僩(忋恾偱偼丄曄姺張棟偍傛傃彂偒崬傒張棟)偼丄擖椡尦偺僐儞億乕僱儞僩偺寢壥僨乕僞偵丄撉傒庢傝壜擻側忬懺(僨乕僞偺惗惉偑姰椆偟偨忬懺)偺僽儘僢僋傪専弌偡傞偲張棟傪奐巒偟傑偡丅撉傒庢傝壜擻側僽儘僢僋傪専弌偱偒側偄忬懺(僨乕僞偺惗惉偑枹姰椆側忬懺)偱偼張棟傪懸婡偟傑偡丅
張棟偺棳傟
乽撉傒庢傝乿-乽曄姺乿-乽彂偒崬傒乿偺娙扨側僒儞僾儖偱丄張棟偺棳傟傪張棟僗僥僢僾偛偲偵愢柧偟傑偡丅
奺僗僥僢僾偺僨乕僞a丄僨乕僞b丄僨乕僞c偼丄撉傒庢傝梡僨乕僞偺1僽儘僢僋傪昞偟傑偡丅
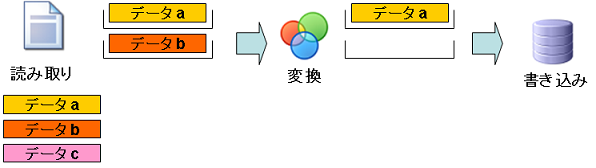
僗僥僢僾1:張棟慜
- 僨乕僞a:傑偩撉傒崬傑傟偰偄傑偣傫丅
- 僨乕僞b:傑偩撉傒崬傑傟偰偄傑偣傫丅
- 僨乕僞c:傑偩撉傒崬傑傟偰偄傑偣傫丅
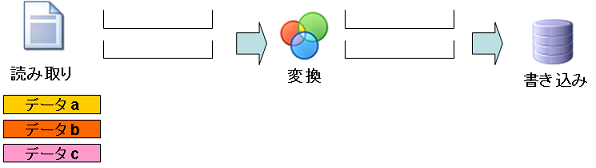
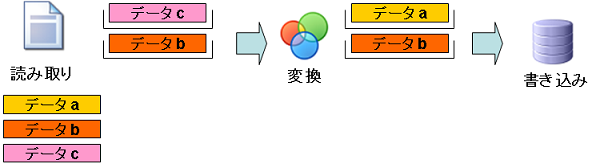
僗僥僢僾2:乽僨乕僞a乿偺撉傒庢傝
- 僨乕僞a:撉傒庢傝張棟偱撉傒崬傑傟丄撉傒庢傝僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
- 僨乕僞b:傑偩撉傒崬傑傟偰偄傑偣傫丅
- 僨乕僞c:傑偩撉傒崬傑傟偰偄傑偣傫丅
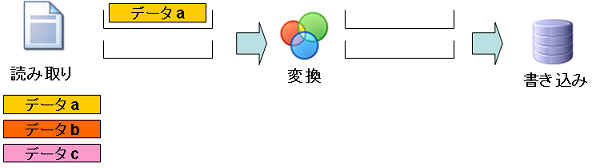
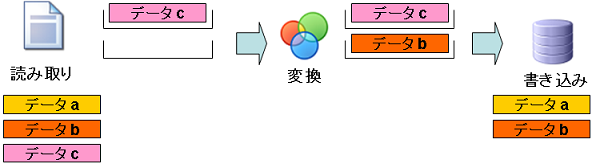
僗僥僢僾3:乽僨乕僞b乿偺撉傒庢傝偲乽僨乕僞a乿偺曄姺
- 僨乕僞a:曄姺張棟偱曄姺偝傟丄曄姺僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
- 僨乕僞b:撉傒庢傝張棟偱撉傒崬傑傟丄撉傒庢傝僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
- 僨乕僞c:傑偩撉傒崬傑傟偰偄傑偣傫丅
 偡傋偰偺張棟偑暲峴偱峴傢傟傑偡丅
偡傋偰偺張棟偑暲峴偱峴傢傟傑偡丅
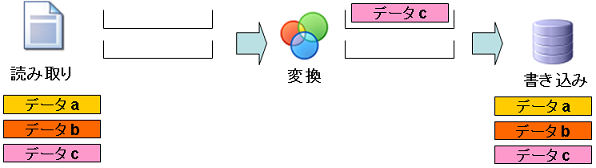
僗僥僢僾4:乽僨乕僞c乿偺撉傒庢傝偲乽僨乕僞b乿偺曄姺偍傛傃乽僨乕僞a乿偺彂偒崬傒
- 僨乕僞a:彂偒崬傒張棟偱幚嵺偵僨乕僞偑彂偒崬傑傟傑偡丅傑偨丄曄姺張棟偑姰椆偟偰偄傞偺偱丄撉傒庢傝張棟偺僽儘僢僋偐傜嶍彍偝傟傑偡丅
- 僨乕僞b:曄姺張棟偱曄姺偝傟丄曄姺僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
- 僨乕僞c:撉傒庢傝僐儞億乕僱儞僩偺僽儘僢僋偑嬻偄偨偺偱丄撉傒庢傝張棟偱撉傒崬傑傟丄撉傒庢傝僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
偡傋偰偺張棟偑暲峴偱峴傢傟傑偡丅
僗僥僢僾5:乽僨乕僞c乿偺曄姺偲乽僨乕僞b乿偺彂偒崬傒
- 僨乕僞a:彂偒崬傒張棟傑偱廔椆偟偰偄傑偡丅
- 僨乕僞b:彂偒崬傒張棟偱幚嵺偵僨乕僞偑彂偒崬傑傟傑偡丅傑偨丄曄姺張棟偑姰椆偟偰偄傞偺偱丄撉傒庢傝張棟偺僽儘僢僋偐傜嶍彍偝傟傑偡丅
- 僨乕僞c:曄姺張棟偱曄姺偝傟丄曄姺僐儞億乕僱儞僩偺僽儘僢僋偵奿擺偝傟傑偡丅
偡傋偰偺張棟偑暲峴偱峴傢傟傑偡丅
僗僥僢僾6:乽僨乕僞c乿偺彂偒崬傒
- 僨乕僞a:彂偒崬傒張棟傑偱廔椆偟偰偄傑偡丅
- 僨乕僞b:彂偒崬傒張棟傑偱廔椆偟偰偄傑偡丅
- 僨乕僞c:彂偒崬傒張棟偱幚嵺偵僨乕僞偑彂偒崬傑傟傑偡丅傑偨丄曄姺張棟偑姰椆偟偰偄傞偺偱丄撉傒庢傝張棟偺僽儘僢僋偐傜嶍彍偝傟傑偡丅
偡傋偰偺張棟偑暲峴偱峴傢傟傑偡丅
偙偺傛偆偵丄僨乕僞傪僽儘僢僋扨埵偵暘妱偟丄偦偺僽儘僢僋扨埵傪暲峴偟偰張棟偡傞偙偲偱丄挻戝梕検僨乕僞傪崅懍偵張棟偟偰偄傑偡丅
僗儅乕僩僐儞僷僀儔偵傛傝丄僗僋儕僾僩偺撪梕傪帺摦敾暿偟偰僷儔儗儖僗僩儕乕儈儞僌張棟傪揔梡偟傑偡丅
偦偺偨傔丄婎杮揑偵偼僷儔儗儖僗僩儕乕儈儞僌傪堄幆偡傞偙偲側偔僗僋儕僾僩傪嶌惉偡傞偙偲偑壜擻偱偡丅
 徻嵶偵偮偄偰偼丄乽僗儅乕僩僐儞僷僀儔乿傪嶲徠偟偰偔偩偝偄丅
PSP偵懳墳偡傞僐儞億乕僱儞僩偲Mapper儘僕僢僋偵偮偄偰偼僿儖僾傪嶲徠偟偰偔偩偝偄丅
徻嵶偵偮偄偰偼丄乽僗儅乕僩僐儞僷僀儔乿傪嶲徠偟偰偔偩偝偄丅
PSP偵懳墳偡傞僐儞億乕僱儞僩偲Mapper儘僕僢僋偵偮偄偰偼僿儖僾傪嶲徠偟偰偔偩偝偄丅
PSP偵懳墳偡傞僐儞億乕僱儞僩偺僆儁儗乕僔儑儞偵偮偄偰偼丄奺僆儁儗乕僔儑儞偺儁乕僕傪嶲徠偟偰偔偩偝偄丅
PSP偵懳墳偡傞Mapper儘僕僢僋偵偮偄偰偼丄乽Mapper儘僕僢僋堦棗乿傪嶲徠偟偰偔偩偝偄丅
慜崁偱愢柧偟偨傛偆偵丄PSP偱偼暋悢偺僗儗僢僪偑嫤挷偟偰張棟傪峴偄傑偡丅
PSP偱偼僗僋儕僾僩偺僗儗僢僪偺傎偐偵丄寢壥僨乕僞傪惗惉偡傞(擖椡尦偲側傞)僐儞億乕僱儞僩偺悢偩偗僗儗僢僪偑惗惉偝傟傑偡丅寢壥僨乕僞傪惗惉偟側偄彂偒崬傒僐儞億乕僱儞僩偵娭偟偰偼丄僗僋儕僾僩偲摨偠僗儗僢僪偱摦嶌偟傑偡丅
偨偲偊偽丄乽撉傒庢傝乿-乽曄姺乿-乽彂偒崬傒乿偺僗僋儕僾僩偱偼丄惗惉偡傞僗儗僢僪悢偼乽3乿偲側傝傑偡丅
乽撉傒庢傝乿-乽曄姺乿-乽曄姺乿-乽彂偒崬傒乿偺僗僋儕僾僩偱偼丄惗惉偡傞僗儗僢僪悢偼乽4乿偲側傝傑偡丅
- 僩儔儞僓僋僔儑儞偑奐巒偟偰偄偨応崌丄PSP偱幚峴偡傞僐儞億乕僱儞僩偼偦偺僩儔儞僓僋僔儑儞偵懏偟傑偡丅
- 僩儔儞僓僋僔儑儞偑奐巒偟偰偄側偄応崌丄PSP偱幚峴偡傞僐儞億乕僱儞僩偼愱梡偺僩儔儞僓僋僔儑儞傪奐巒偟傑偡丅
偦偺偨傔丄摨偠僌儘乕僶儖儕僜乕僗傪巊梡偡傞僐儞億乕僱儞僩偑暋悢懚嵼偟丄偄偢傟偐偑PSP偱幚峴偡傞応崌丄暿乆偺僐僱僋僔儑儞傪巊梡偟傑偡丅
- PSP偱偼丄寢壥僨乕僞傪暋悢偺僐儞億乕僱儞僩偺擖椡尦偵巜掕偡傞偙偲偼偱偒傑偣傫丅
- 曄悢Mapper偱丄擖椡僪僉儏儊儞僩偐傜曄悢偵儅僢僺儞僌偟偰偄傞応崌傕擖椡尦傊偺巜掕偵偁偨傝傑偡丅
- 僄儔乕偵偮偄偰
- PSP偱偼丄撉傒庢傝傗曄姺僐儞億乕僱儞僩偱敪惗偟偨僄儔乕偼丄彂偒崬傒僐儞億乕僱儞僩偺僄儔乕偲偟偰張棟偝傟傑偡丅僄儔乕偺撪梕偵偮偄偰偼丄PSP僇僥僑儕偺儊僢僙乕僕僐乕僪傪妋擣偟偰偔偩偝偄丅
- PSP偱偼丄撉傒庢傝傗曄姺僐儞億乕僱儞僩偱敪惗偟偨僄儔乕偼丄曄姺僐儞億乕僱儞僩傪擖椡尦偵庢傞僐儞億乕僱儞僩偑懚嵼偟側偄応崌偵偼丄僄儔乕偲偟偰張棟偝傟傑偣傫丅
偨偲偊偽丄PSP偑揔梡偝傟偰偄傞撉傒庢傝僐儞億乕僱儞僩偱僄儔乕偑敪惗偟偰傕丄僗僋儕僾僩偼惉岟偟丄僄儔乕儊僢僙乕僕偼儘僌偵弌椡偝傟傑偣傫丅
- PSP偱張棟傪峴偆撉傒庢傝僐儞億乕僱儞僩偲彂偒崬傒僐儞億乕僱儞僩偺娫偱丄張棟懳徾偲側傞僼傽僀儖偼憖嶌偱偒傑偣傫丅
- PSP偱偼丄堦晹偺僐儞億乕僱儞僩曄悢偑巊梡偱偒傑偣傫丅
徻嵶偵偮偄偰偼丄奺僆儁儗乕僔儑儞偺僿儖僾傪嶲徠偟偰偔偩偝偄丅
- PSP偱偼丄寢壥僨乕僞傪嶌惉偡傞僐儞億乕僱儞僩偑幚峴偝傟偨嵺偵僗儗僢僪偑嶌惉偝傟傑偡丅
- 僽儘僢僋僒僀僘傪曄峏偡傞偙偲偼偱偒傑偣傫丅
- 堷悢偐傜偺僨乕僞僼儘乕傗Mapper娫偺僨乕僞僼儘乕偺応崌偵偼丄Mapper偱乽僗僉乕儅偺愝掕乿傪峴偆偙偲偑偱偒傑偡偑丄乽僥乕僽儖儌僨儖宆乿埲奜偺僗僉乕儅偵曄峏偡傞偲 PSP懳墳Mapper偲偟偰摦嶌偟傑偣傫丅
偮傑傝丄戝梕検偺僨乕僞傪埖偆応崌偵偼儊儌儕傪妋曐偡傞昁梫偑偁傝傑偡丅PSP傪揔梡偡傞応崌偵偼丄Mapper偺僗僉乕儅傪僥乕僽儖儌僨儖宆埲奜偺僗僉乕儅(乽XML宆乿)偵曄峏偟側偄傛偆偵偟偰偔偩偝偄丅
拲堄帠崁
PSP偺寢壥僨乕僞偑忦審暘婒僐儞億乕僱儞僩偵傛傝巊梡偝傟側偐偭偨応崌丄僷僼僅乕儅儞僗偑楎壔偟傑偡丅
PSP僨乕僞僼儘乕傪柍岠壔偡傞偙偲偱丄僷僼僅乕儅儞僗楎壔傪杊偖偙偲偑偱偒傑偡丅
埲壓偺僗僋儕僾僩偼丄CSV僼傽僀儖傪堦峴偢偮撉傒庢傝丄偦偺峴偑偁傞忦審傪枮偨偡応崌偵CSV僼傽僀儖偵彂偒崬傓張棟偱偡丅儅僢僺儞僌偲CSV僼傽僀儖傊偺彂偒崬傒偺娫偱PSP僨乕僞僼儘乕偑桳岠偵側偭偰偍傝丄忦審偵崌抳偟側偄応崌偵僷僼僅乕儅儞僗偑楎壔偟傑偡丅